
Hi This is my first Blog hope you guys like this 🙂
Followings are the topics which i will cover in the blog :-
1. What is BigData
2. BigData Projects
3. BigData Technologies
Lets start from the scratch :-
What is data :-
According to wikipidea :- Data is a set of values of qualitative or quantitative variables; restated, pieces of data are individual pieces of information. Data is measured, collected and reported, and analyzed, whereupon it can be visualized using graphs or images. Data as a general concept refers to the fact that some existinginformation or knowledge is represented or coded in some form suitable for better usage or processing.
in short :- data is basically a piece/part of information ( it can be any message , image , email etc ) which means :- data + data + data = information . OR Data is distinct pieces of information, usually FORMATTED in a special way .
lets explain point 1 :-
which is 1. What is BigData
BIG DATA :- At first impression , the data which is big can be known as big data ,which is correct upto some extent. But actually BigData is defined as :-
it is nothing it is just a catchy word which is generally use for a data which is massive in amount , can be structured or unstructured , may be bulk information , bulk images anything which is massive in size is known as Bigdata .
for eg :- 1 TB of log file , 2 TB of image files , or sensors gathered climate information , these are just some examples we will learn more when we go further in this blog .
In technical World :-
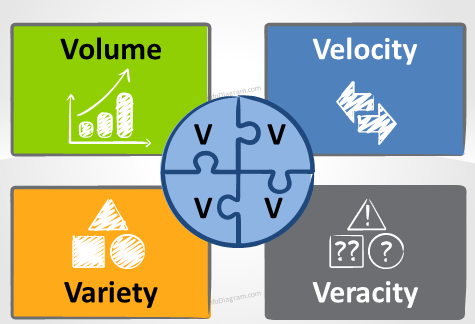
BigData contains 4V’s or the data which contain below 4 V’s characteristic is known as BigData :-
a. Volume :- As name suggests 1st thing comes into mind is massive , means volume of data .
Volume of data is like :- the quantity of data generated must be massive or very much in volume (quantity ) , generally >10 GB data is considered as BIGDATA
size can be vary from GB’S to TB’s to PB’s
for eg :- Google process many petabyte data per day
b)Variety – The next aspect of Big Data is its variety. This means that the category to which Big Data belongs to is also a very essential fact that needs to be known by the data analysts. This helps the people, who are closely analyzing the data and are associated with it, to effectively use the data to their advantage and thus upholding the importance of the Big Data.
Unstructured data is a fundamental concept in big data. The best way to understand unstructured data is by comparing it to structured data. Think of structured data as data that is well defined in a set of rules. For example, money will always be numbers and have at least two decimal points; names are expressed as text; and dates follow a specific pattern.
With unstructured data, on the other hand, there are no rules. A picture, a voice recording, a tweet — they all can be different but express ideas and thoughts based on human understanding. One of the goals of big data is to use technology to take this unstructured data and make sense of it
It can be sourced out from emails, audio and video forms.
c)Velocity – The term ‘velocity’ in the context refers to the speed of generation of data or how fast the data is generated and processed to meet the demands and the challenges which lie ahead in the path of growth and development.
Think about how many SMS messages, Facebook status updates, or credit card swipes are being sent on a particular telecom carrier every minute of every day, and you’ll have a good appreciation of velocity. A streaming application like Amazon Web Services Kinesis is an example of an application that handles the velocity of data.
d)Veracity – The quality of the data being captured can vary greatly. Accuracy of analysis depends on the veracity of the source data.
Hope , now you can understand what bigdata is 🙂
Lets come to point number 2 :-
2.Big Data Projects
Here’s another way to capture what a Big Data project could mean for your company or project: study how others have applied the idea.
Here are some real-world examples of Big Data in action:
- Consumer product companies and retail organizations are monitoring social media like Facebook and Twitter to get an unprecedented view into customer behavior, preferences, and product perception.
- Manufacturers are monitoring minute vibration data from their equipment, which changes slightly as it wears down, to predict the optimal time to replace or maintain. Replacing it too soon wastes money; replacing it too late triggers an expensive work stoppage
- Manufacturers are also monitoring social networks, but with a different goal than marketers: They are using it to detect aftermarket support issues before a warranty failure becomes publicly detrimental.
- The government is making data public at both the national, state, and city level for users to develop new applications that can generate public good. Learn how government agencies significantly reduce the barrier to implementing open data with NuCivic Data
- Financial Services organizations are using data mined from customer interactions to slice and dice their users into finely tuned segments. This enables these financial institutions to create increasingly relevant and sophisticated offers.
- Advertising and marketing agencies are tracking social media to understand responsiveness to campaigns, promotions, and other advertising mediums.
- Insurance companies are using Big Data analysis to see which home insurance applications can be immediately processed, and which ones need a validating in-person visit from an agent.
- By embracing social media, retail organizations are engaging brand advocates, changing the perception of brand antagonists, and even enabling enthusiastic customers to sell their products.
- Hospitals are analyzing medical data and patient records to predict those patients that are likely to seek readmission within a few months of discharge. The hospital can then intervene in hopes of preventing another costly hospital stay.
- Web-based businesses are developing information products that combine data gathered from customers to offer more appealing recommendations and more successful coupon programs.
- Sports teams are using data for tracking ticket sales and even for tracking team strategies.
3. BigData Technologies :-
As this much bigData cannot be handled by simpler means of RDBMS( because normal databases have their limits to store data , as well RDBMS works on strucred data (bigdata = structured or Unstructured or Semi structured)
Here are the following technologies which are to be used for handling of bigdata :-
1.Apache Hadoop
2.Apache Mapreduce , Spark , HDFS etc etc.
We will learn these techniques in coming blogs but for now ,
what is BigData knowledge is sufficient , Hop u understand what is actually a BigData
Intrestinmg Examples :-
- According to IBM, 80% of data captured today is unstructured, from sensors used to gather climate information, posts to social media sites, digital pictures and videos, purchase transaction records, and cell phone GPS signals, to name a few. All of this unstructured data is Big Data.
-
-
A9.com – Amazon*
-
We build Amazon’s product search indices using the streaming API and pre-existing C++, Perl, and Python tools.
-
We process millions of sessions daily for analytics, using both the Java and streaming APIs.
-
Our clusters vary from 1 to 100 nodes
-
-
-
We use an Apache Hadoop cluster to rollup registration and view data each night.
-
Our cluster has 10 1U servers, with 4 cores, 4GB ram and 3 drives
-
Each night, we run 112 Hadoop jobs
-
It is roughly 4X faster to export the transaction tables from each of our reporting databases, transfer the data to the cluster, perform the rollups, then import back into the databases than to perform the same rollups in the database.
-
-
-
We use Apache Hadoop and Apache HBase in several areas from social services to structured data storage and processing for internal use.
-
We currently have about 30 nodes running HDFS, Hadoop and HBase in clusters ranging from 5 to 14 nodes on both production and development. We plan a deployment on an 80 nodes cluster.
-
We constantly write data to Apache HBase and run MapReduce jobs to process then store it back to Apache HBase or external systems.
-
Our production cluster has been running since Oct 2008.
-
-
-
We use Apache Flume, Apache Hadoop and PApache ig for log storage and report generation as well as ad-Targeting.
-
We currently have 12 nodes running HDFS and Pig and plan to add more from time to time.
-
50% of our recommender system is pure Pig because of it’s ease of use.
-
Some of our more deeply-integrated tasks are using the streaming API and ruby as well as the excellent Wukong-Library.
-
-
Able Grape – Vertical search engine for trustworthy wine information
-
We have one of the world’s smaller Hadoop clusters (2 nodes @ 8 CPUs/node)
-
Hadoop and Apache Nutch used to analyze and index textual information
-
-
Adknowledge – Ad network
-
Hadoop used to build the recommender system for behavioral targeting, plus other clickstream analytics
-
We handle 500MM clickstream events per day
-
Our clusters vary from 50 to 200 nodes, mostly on EC2.
-
Investigating use of R clusters atop Hadoop for statistical analysis and modeling at scale.
-
-
Aguja– E-Commerce Data analysis
-
We use hadoop, pig and hbase to analyze search log, product view data, and analyze all of our logs
-
3 node cluster with 48 cores in total, 4GB RAM and 1 TB storage each.
-
-
-
A 15-node cluster dedicated to processing sorts of business data dumped out of database and joining them together. These data will then be fed into iSearch, our vertical search engine.
-
Each node has 8 cores, 16G RAM and 1.4T storage.
-
-
-
We use Apache Hadoop for variety of things ranging from ETL style processing and statistics generation to running advanced algorithms for doing behavioral analysis and targeting.
-
The cluster that we use for mainly behavioral analysis and targeting has 150 machines, Intel Xeon, dual processors, dual core, each with 16GB Ram and 800 GB hard-disk.
-
-
ARA.COM.TR – Ara Com Tr – Turkey’s first and only search engine
-
We build Ara.com.tr search engine using the Python tools.
-
We use Apache Hadoop for analytics.
-
We handle about 400TB per month
-
Our clusters vary from 10 to 100 nodes
-
-
-
More can be found :- http://wiki.apache.org/hadoop/PoweredBy
Hope this blog create some interest about BigData and understanding of BigData .
Thanks for patience
Cheers .

Thanks for your updater:)
LikeLike
thnks for feedback 🙂
LikeLike